



My second project I did at Hochschule der Medien Stuttgart was to explore different parallelization techniques and to test their use for game development. At this project I worked together with my classmate Kay Plößer. The idea to make this project had our professor Walter Kriha.
In the past traditional games used a single-threaded loop to process events and to render the world. This was fine as long as CPUs had only one core. The life for programmers was easier. If the processing power for a game was not enough, developers just had to wait until the next faster CPU with a higher clock speed was released. It was fact that the same code would run faster on a new CPU.
With the introduction of the multicore processors this free lunch was over. The performance improvement of new CPUs was no longer achieved with a higher clock speed. Instead performance improvements have been established through multicore architecture and hyper threading. This led to a fundamental change in software development as well as in game development.
First multithreading in games was done with separating the different parts of the engine in threads. Processing for game mechanics, rendering, physics, networking, artificial intelligence and sounds were done in different threads. The advantage of this approach was that existing game code could be reused. Just find the parts of your game engine which act independent of each other and put them into different threads.
But there were some problems with this approach. Only a limited number of parts could be separated into threads. This means that this approach only works for a small number of cores and could only be optimized for a constant number of cores. It is also possible that these parts do not have the same amount of processing to do. This leads to the behavior that threads wait for the other threads to finish. In this case several cores of the CPU are not used. Additionally, parts are not totally independent of each other. This leads to shared state. Shared state is data that two or more threads read and modify. To prevent inconsistent data shared state need to be handled. First it was tried to handle shared state with locks. With a lock, only one thread gets the permission to modify data while the other threads are not allowed to access the data at the same time. But locking had the big problem of deadlocks. And even if locking was handled correct, it could lead to serial processing, which we do not want to have in a multithreaded environment. Another issue with this approach is that context switches of these threads are expensive. It is reasonable to use as many threads as cores are available to avoid context switches. However, this leads to an optimization for a constant number of cores. There is no performance boost with a higher number of cores.
This first approach was not the answer for making games multithreaded. This is where the work for our project started. We wanted to find out how we can program in parallel to be prepared for the future. Wouldn’t it be nice when we could have the free launch again? That our code would run faster on a new CPU with more cores without changing anything of our code? Yes it would. But how can we achieve this?
There are three approaches that have been done in software development: Software Transactional Memory, Job Management and Actor Model.
The idea of Software Transactional Memory is that commands, which are related to shared state, are combined into a transaction. After each transaction it is checked if the data is consistent. If that is not the case the transaction can be rolled back and processing needs to be done again. This technique has the big advantage that there are no deadlocks and data is never inconsistent. However, it also has a big overhead, which is bad for performance of the application. Additionally, there is the same problem with context switches as in the previous approach. Therefore Software Transactional Memory is not applicable for the free launch paradigm.
In Job Management all calculations are defined into jobs, which are totally independent of each other. These jobs are performed by worker threads. The number of worker threads is dependent on the cores of the system. A four core CPU would have four worker threads and a six core CPU would have six worker threads. At the definition of a job every data that the job needs for processing is provided. After definition the job is set into a queue of a worker thread. The worker thread will process the job as soon as free resources are available. Job Management has the big advantage that there is no shared data. Therefore locks are not needed. Job Management scales with the number of cores and context switches are minimized. However, it needs an intelligent manager that distributes the jobs between the available worker threads. Furthermore, programmers have to define jobs instead of functions. This increases programming effort.
The basic idea of an Actor Model is that every object in the system is an actor. Every actor is a thread or a job. An actor has a predefined task. It runs until it has finished its task. Actors do not have shared state. They communicate with each other via messages. An actor can send messages to actors and receive messages from actors. An actor is also able to create other actors. The big advantage of this model is that every actor can run in parallel. Dependencies between actors can be implemented with messages. There is no locking. Data can be sent and received synchronously or asynchronously. It scales with the number of cores and reduces context switches. However, messaging has an overhead and increases development effort.
Job Management and Actor Model used with jobs seem to be the solution for the free lunch paradigm because they both scale better with number of cores. Job Management is more suitable when independent parts can be processed at the same time and Actor Model is more suitable when dependencies need to be considered.
We thought the Actor Model really fits well to the game objects. So we decided that every game object should be an actor. Dependencies between the game objects should be done via messaging. With this approach the number of possible game objects should be directly dependent on the number of available cores.
First we needed to decide which programming language we will use for this. Possible languages that implement the Actor Model are Erlang, Scala and Go. There is also the possibility to use libraries of C++, which implement the Actor Model. However, these libraries sometimes name the Actor Model different. But it is the same concept. Finally, we decided to use the Asynchronous Agents Library of Microsoft’s Concurrency Runtime programming framework for C++. This runtime is exclusive for Windows and can be used with Visual Studio 2010. Visual Studio 2010 provides debugging tools, which were developed for Microsoft’s Concurrency Runtime. With these tools it is possible to see exactly how many resources of the CPU are used. The Asynchronous Agent Library implements the Actor Model. An actor is here called agent. Each agent generates a task. This is the same as a job of the Job Management approach. These tasks are handled of the Concurrency Runtime with its Task Scheduler and Resource Manager. Messaging between agents can be done with message-blocks.

Architecture of Microsoft's Concurrency Runtime
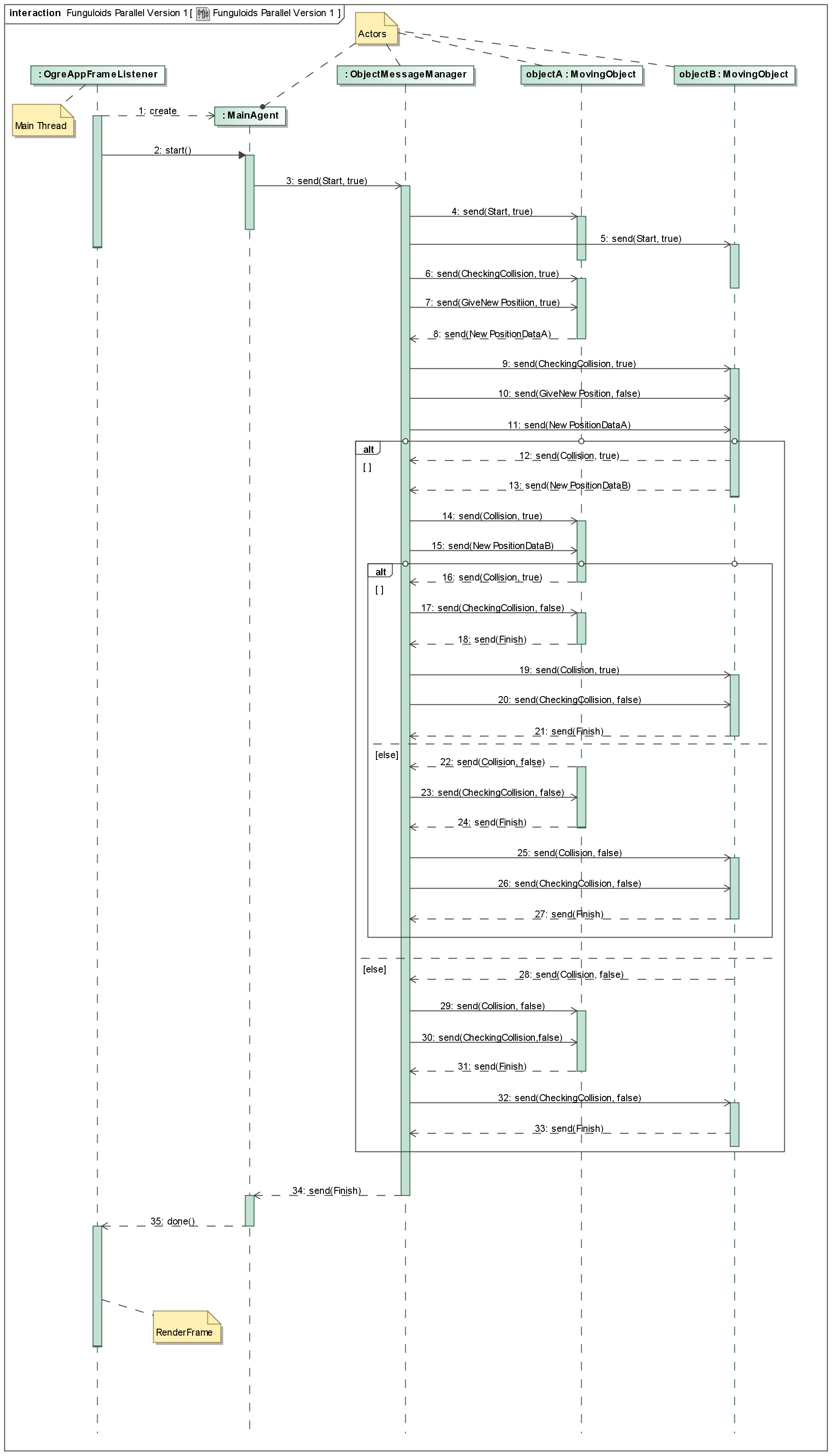
For our implementation we used the Asynchronous Agents Library. Because of the short timeframe we had for our project and to be able to compare a serial version with a parallel version, we decided to use a finished game and parallelize it with the Actor Model. The game we chose was Those Funny Funguloids. This game is open source and uses the open source graphics rendering engine Ogre.

Messaging between two Actors of the Asynchronous Agents Library
In development of our parallel version we were confronted with some problems. The first problem was that we had to solve the question how game objects can communicate with each other when they do not know that other game objects exist? Actors need to know message blocks for communication. The solution of this problem was to make an actor that acts like a communication center. It stores all the game objects and their message blocks. All messages are sent to this actor and it transmits the messages to the corresponding game objects.
Another problem we had was the Ogre engine. This engine is not thread safe. Accessing the data from another thread than the main thread makes the application unstable and leads to rendering errors.
Additionally the dependencies between game objects were higher than we had expected. The result was a lot of messages, which cost us so much performance that the parallel version was a lot slower than the serial version. We will get a performance boost with more cores. But even with more cores there were to much messages. We decided to make a new version to dramatically minimize the number of messages. You can compare the number of messages in the following diagrams. In these diagrams it is shown how game objects communicate with each other. However, reduction of the messages had the cost of additional calculations. For example collision tests have to be performed in each actor.

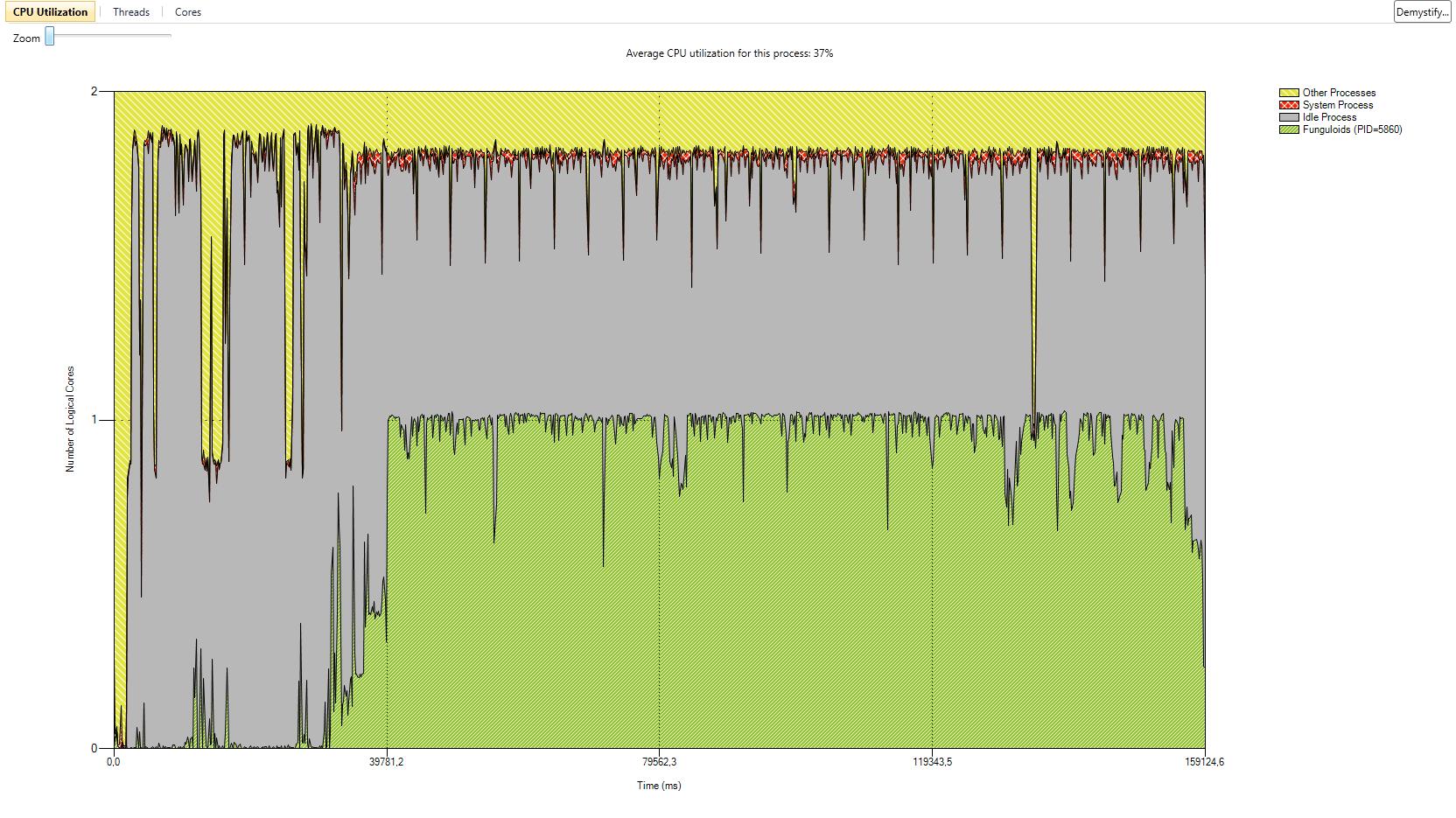
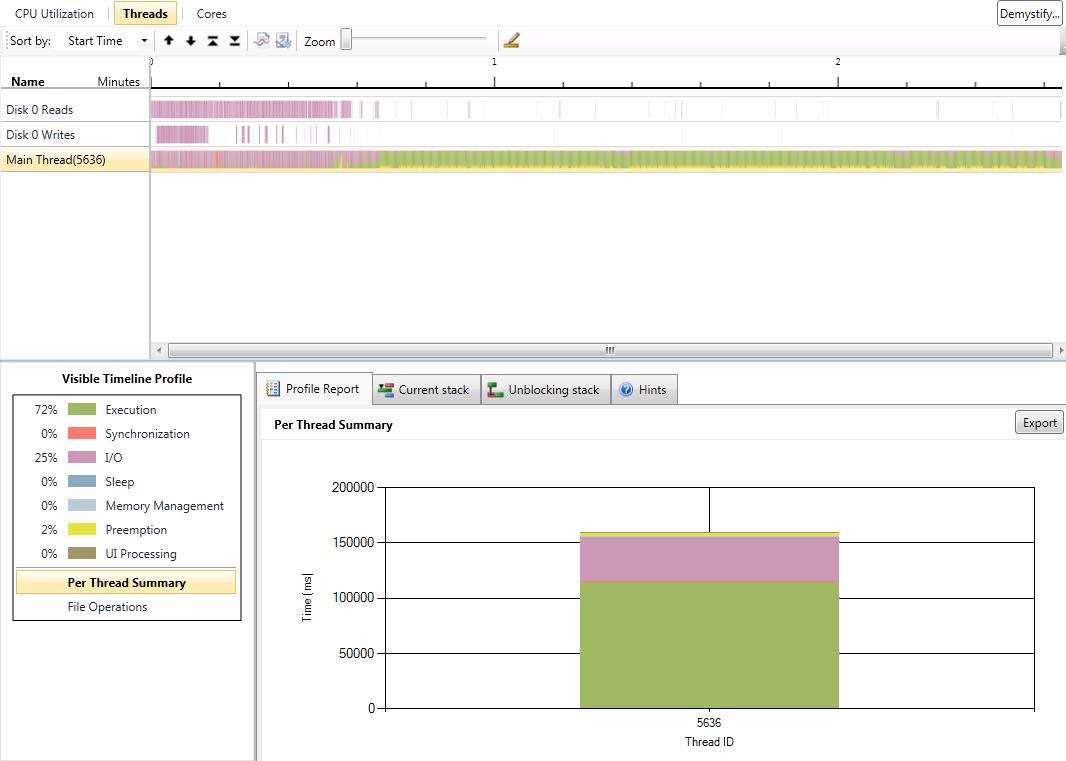
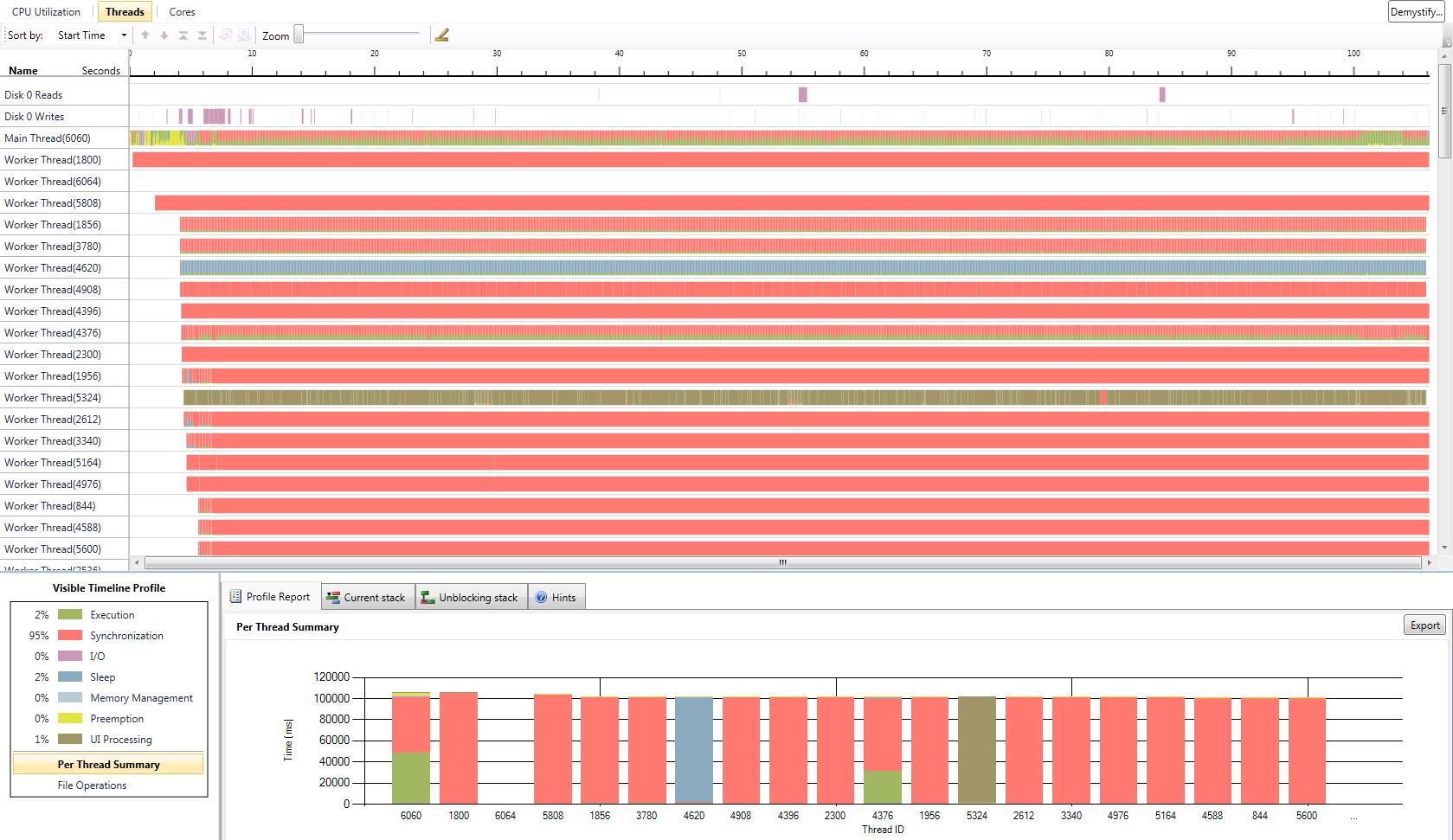
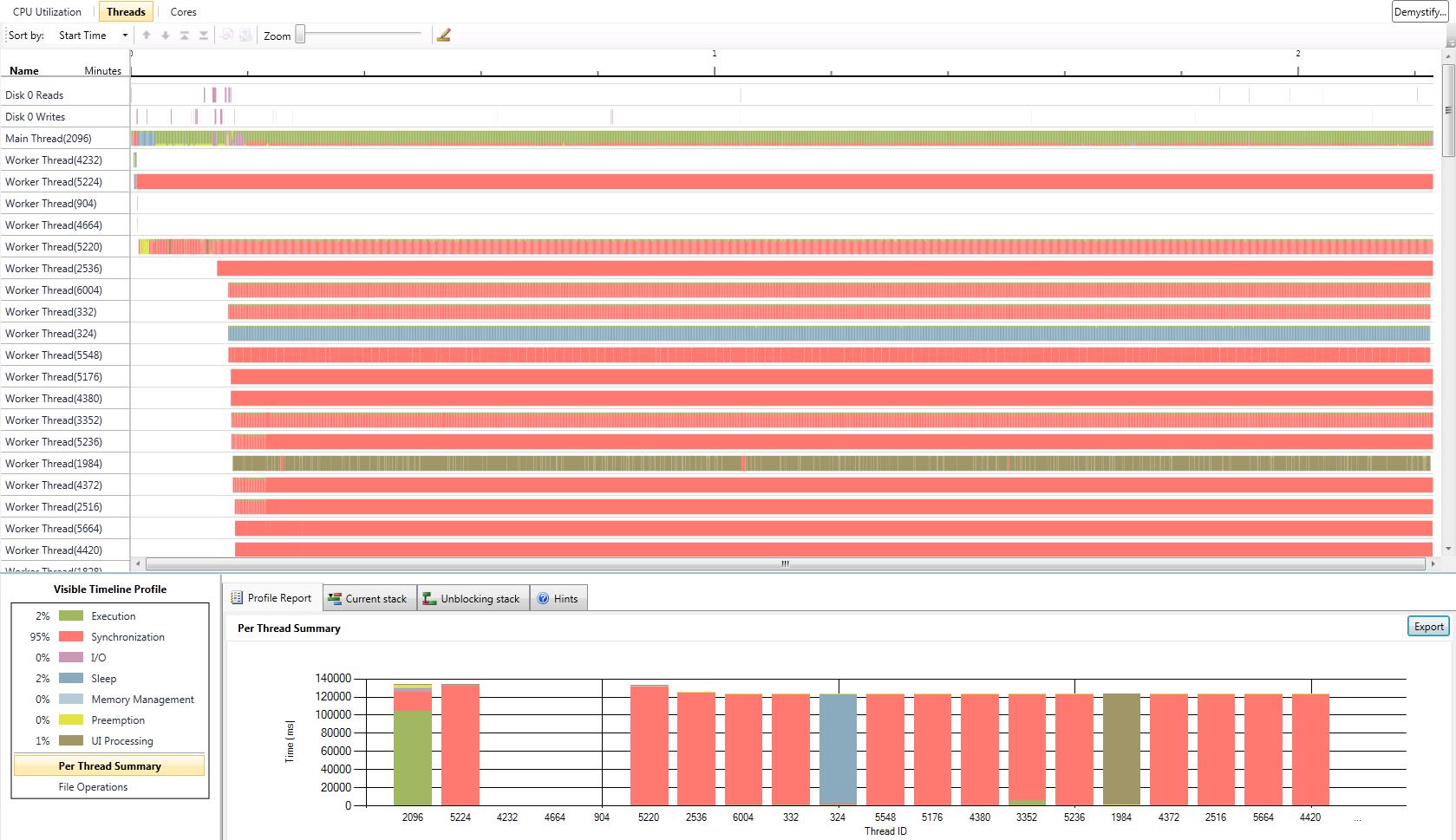
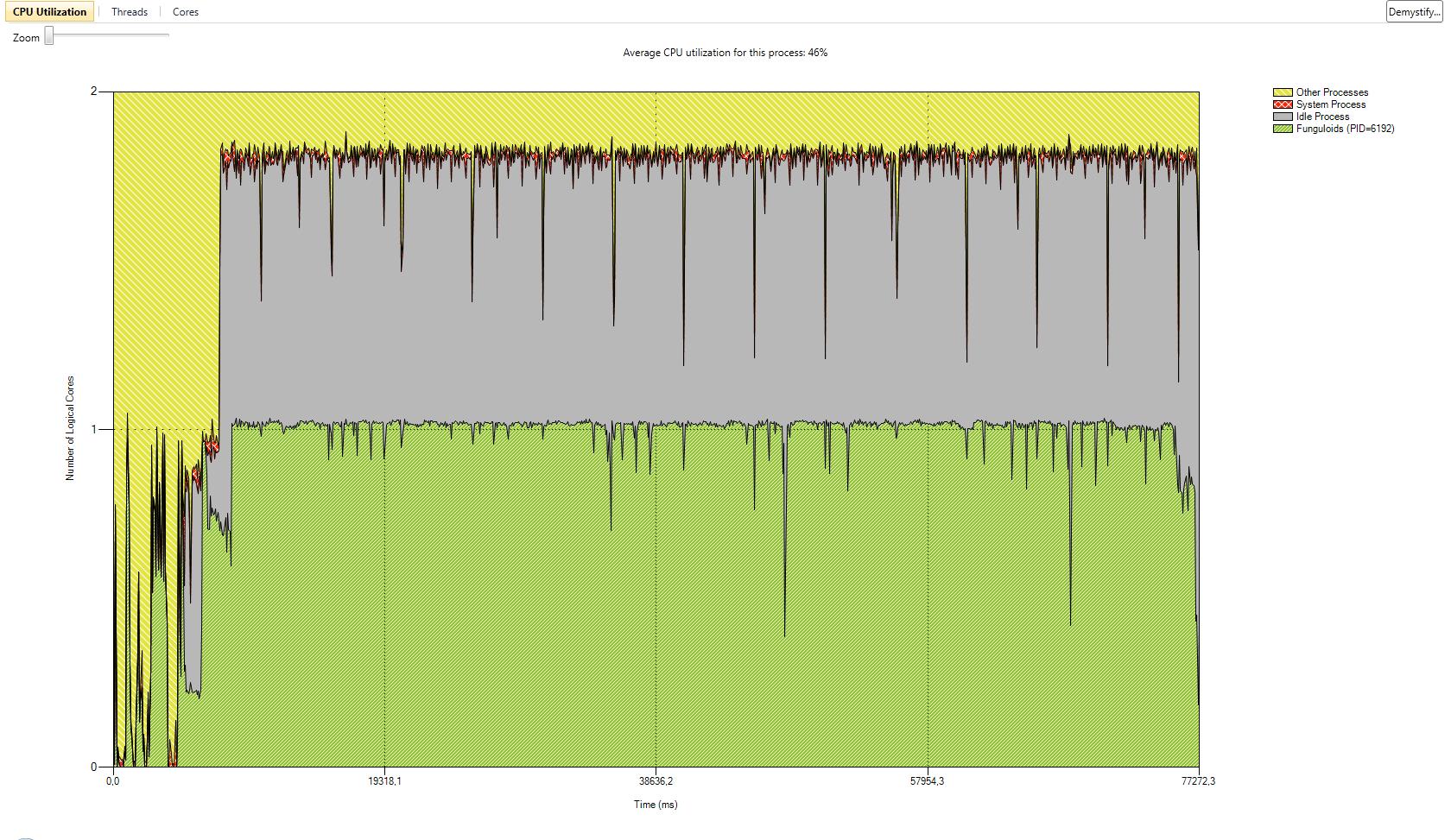
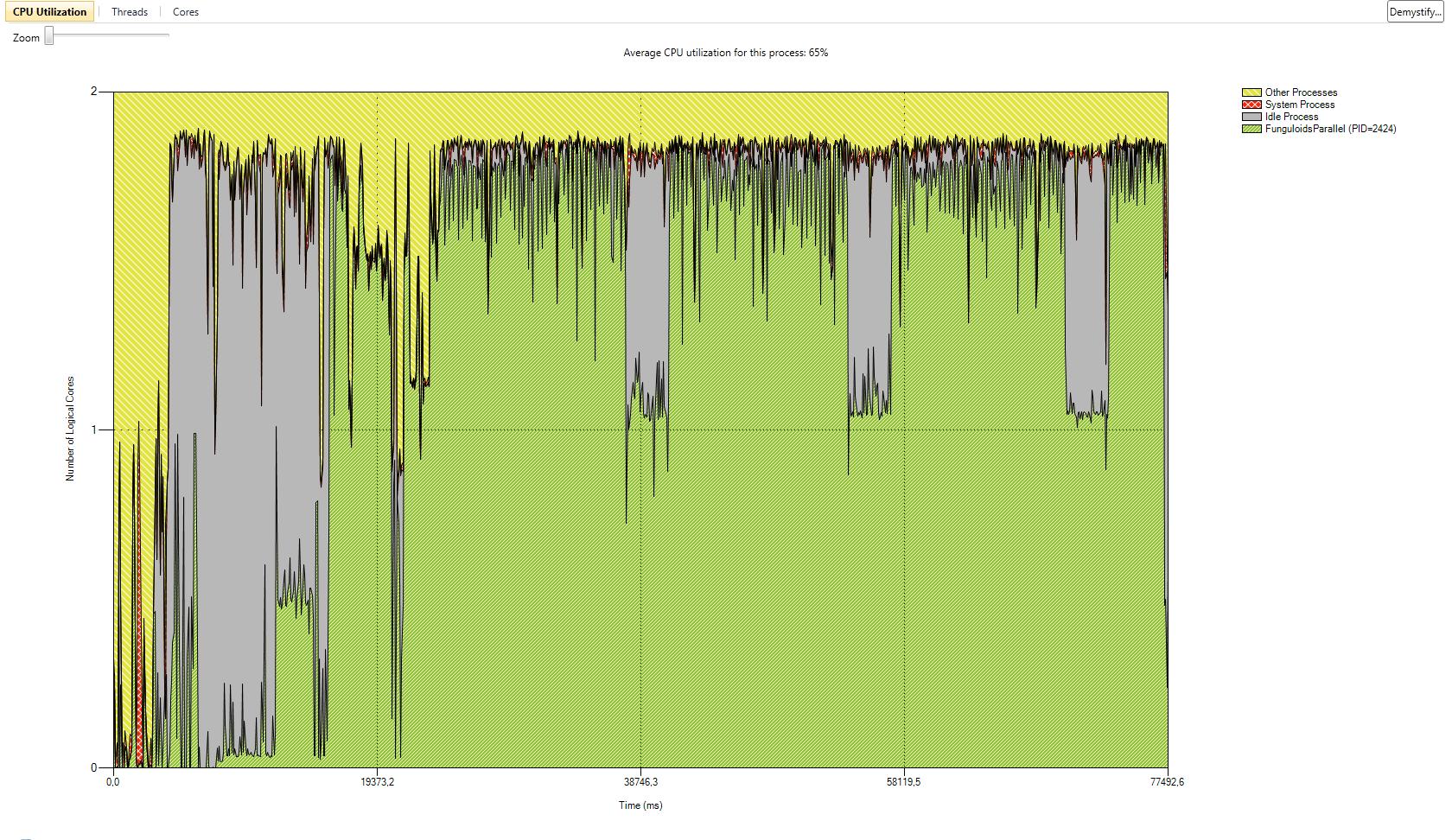
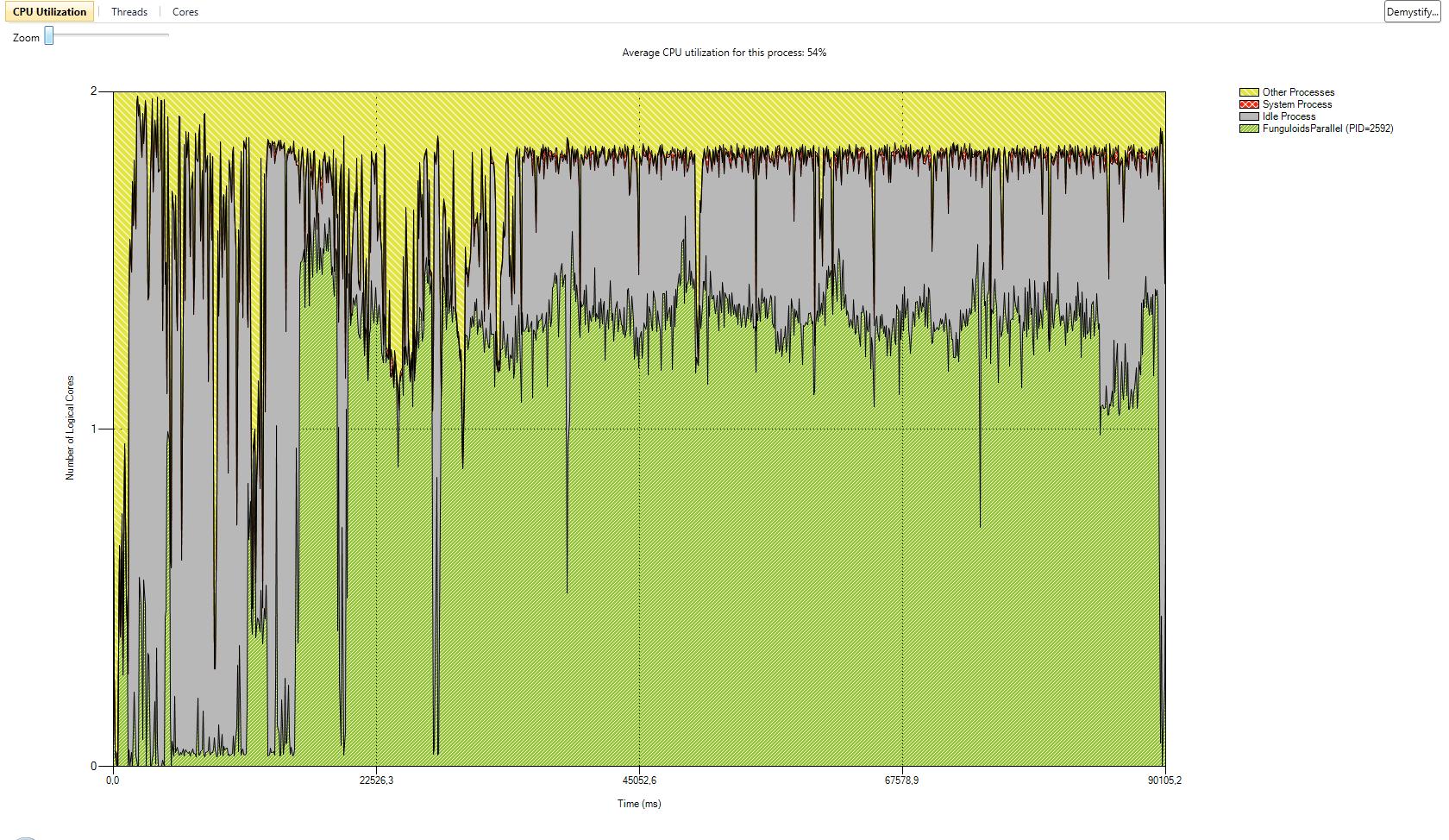
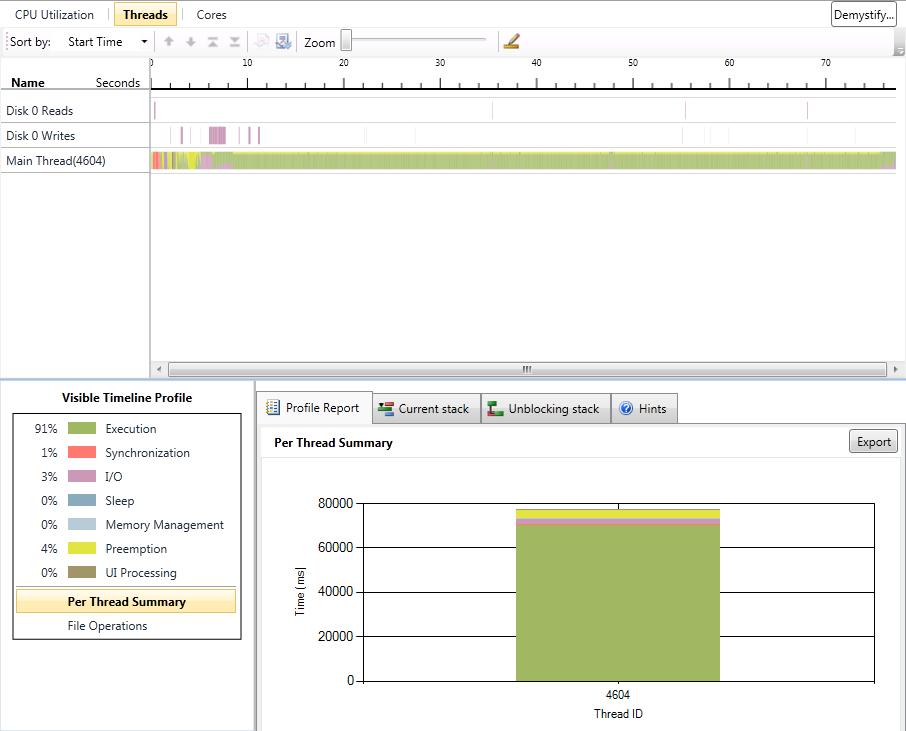
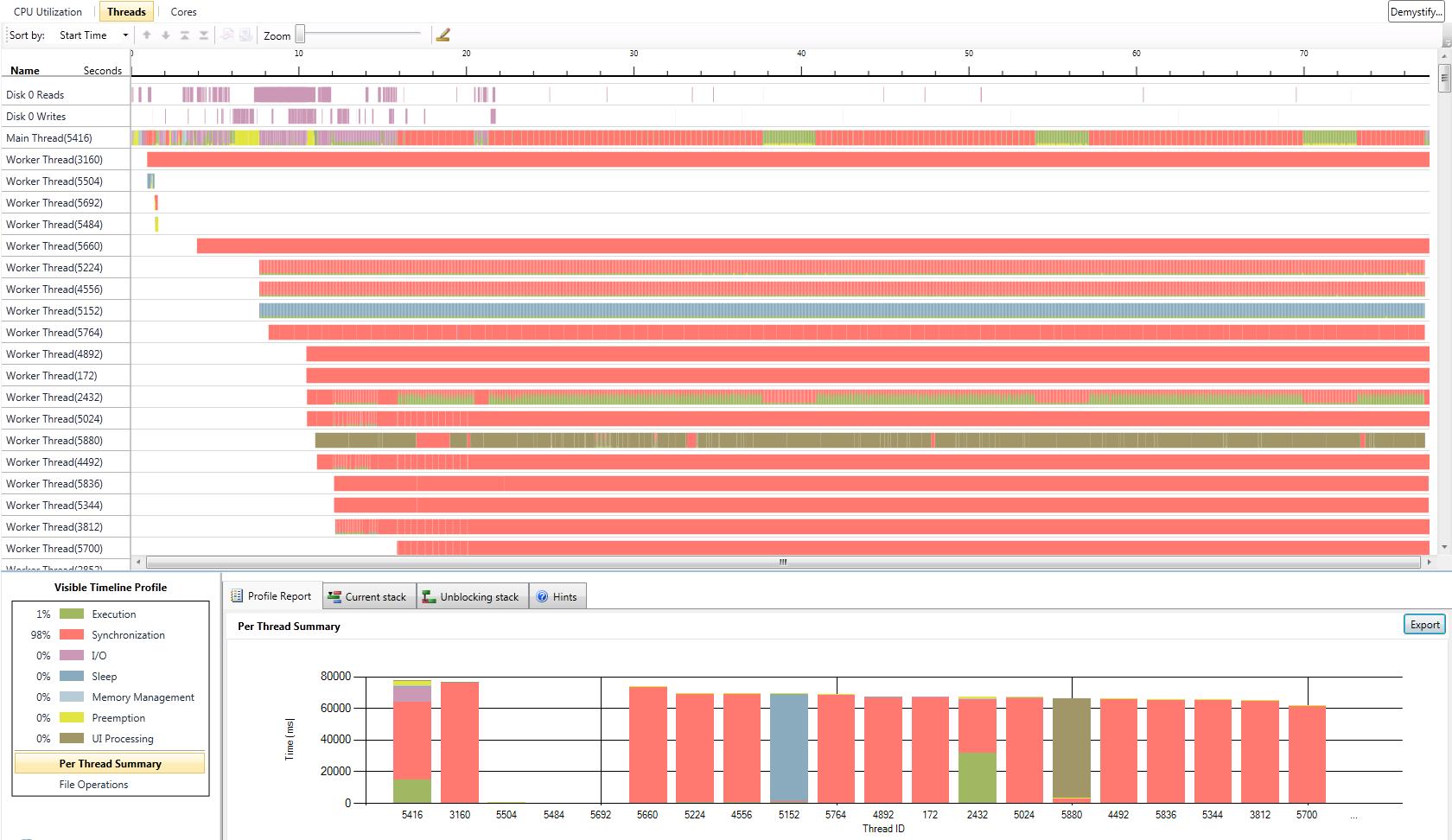
I have also added a gallery with the results of our performance test we did with the serial version and the two parallel versions. The processor we used was a Core 2 Duo with 2 GHz. We tested with two different numbers of game objects. The first test was with the number of game objects that were used in the original game. The second test was with about ten times more game objects. CPU utilization is better in version 1. In some parts of the application almost 100% of the CPU is used. In parallel version 2 the first core is used most of the time with 100%. The second core has a maximum utilization of 50%. The average utilization of the second core is about 30%. This data is related to the second test with ten times more game objects. In both parallel versions the actors are mostly in synchronization state because of the high number of actors and the use of a two core CPU. Reduction of the time actors are in synchronization state is only possible with more CPU cores or less actors.
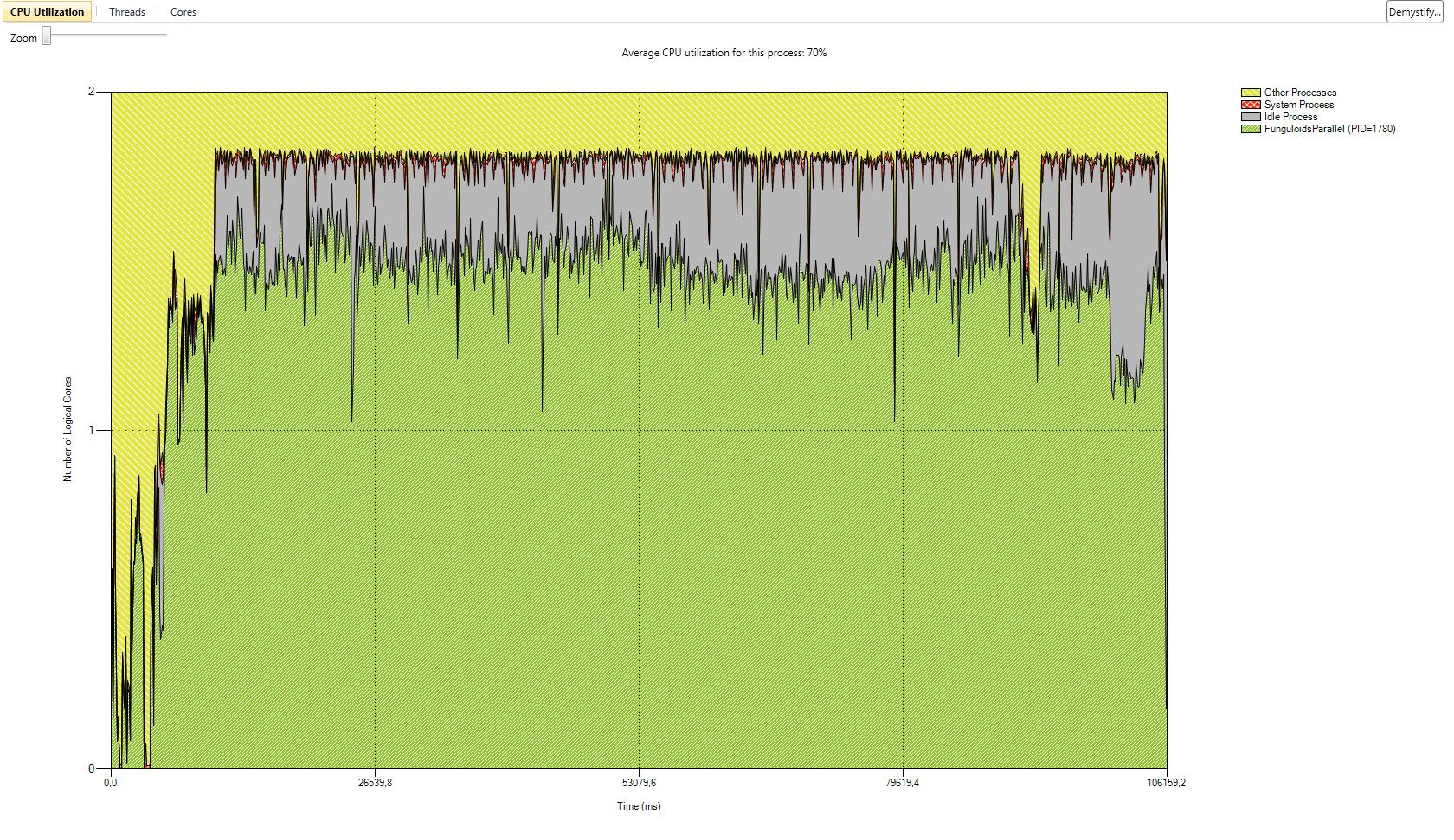
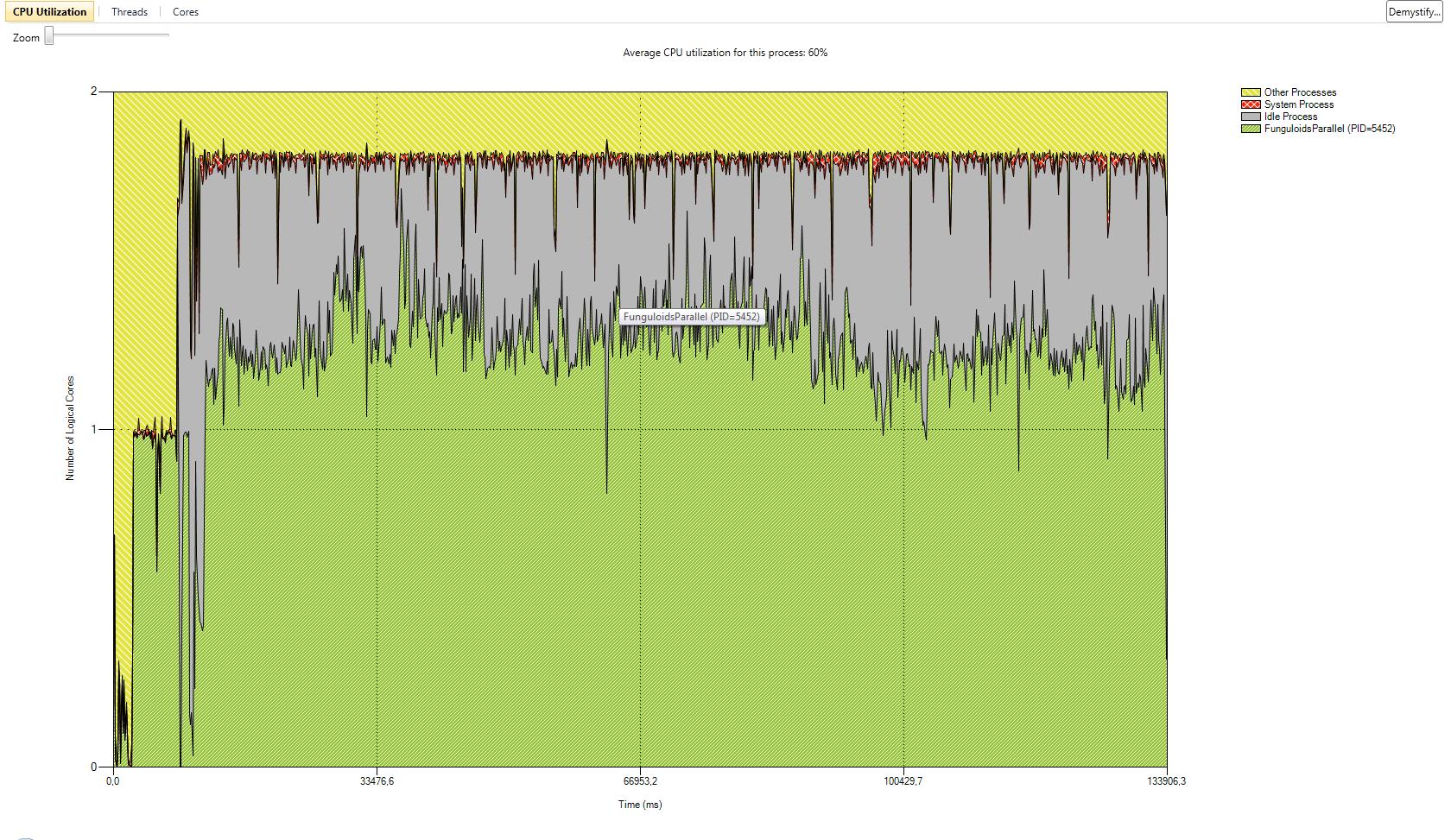
Another performance test with Fraps shows the average frame rate of the applications. The more game objects are added the higher is the performance loss of the parallel applications on a two core CPU compared to the serial version. Especially parallel version 1 loses frame rate because the number of messages massively increases with more game objects. In parallel version 2 the average frames per second are a lot better when game objects are added. The performance loss compared to the version with few objects is also a lot better in parallel version 2. Additional calculations, which need to be done in parallel version 2, are the reason for a higher performance loss compared to the serial version. A CPU with more cores could compensate the additional calculations. This would lead to a reduced performance loss compared to the serial version.

The approach that every game object is an actor needs a high number of cores to perform well. Using the Actor Model as parallelization technique brings an overhead through messages, additional processing and synchronization. It needs to be tested how parallel version 2 works with a higher number of cores. It would be interesting to see how it will perform on a CPU with 1000 cores, which scientists of University of Glasgow have already created.
For a low number of cores Job Management seems to be the better solution. Separating all the processing tasks into independent jobs could work without the overhead that the Actor Model has. Therefore it needs to be explored how calculation of a game engine could be defined into jobs.
Anyway it is clear that we need to find a technique with that parallelism can be easily achieved. Without a suitable technique we will not be able to use the full power of future CPUs. I do not see that this is the case with the Actor Model. The more I have studied about parallelization I got more and more convinced that object oriented programming is not suitable for easy and good parallelization. Maybe we need to change the way to program to achieve great parallelism. For example with graphics cards great parallelism can be achieved through data parallel processing. I think for the future we have to go to a more Data-Oriented Design. Game programming is about data and how this data is being changed according to the actions of the player. The advantages of data oriented design are parallelization, cache utilization, modularity and testing. For more information I recommend the article Data-Oriented Design (Or Why You Might Be Shooting Yourself in The Foot With OOP). I don’t know if everything is true what Noel writes about it. But I think it is worth to try out.
What are your thoughts about parallel programming? Are there any other techniques for parallelization which could be useful for game development? Feel free to post a comment at the end of the page. It would be great if we could start a discussion about this topic. I’m always interested in new parallelization techniques.
Paper
For this project Kay Plößer and I wrote a documentation in German. The documentation can be downloaded here.
2 pings
Welcome to My Blog » Markus Rapp's Blog
January 19, 2012 at 2:45 pm (UTC 2) Link to this comment
[…] Game Development on Multicore […]